डेटाबेस संबंधपरक हैं। संबंधपरक डेटाबेस की अवधारणा
हमारे कंप्यूटर कंप्यूटर का आगमनसूचना आधुनिकता मानव गतिविधि के सभी क्षेत्रों में एक क्रांति के रूप में चिह्नित। लेकिन जानकारी के सभी इंटरनेट में अनावश्यक बर्बादी नहीं बन जाता है करने के लिए, डेटाबेस प्रणाली, जिसमें सामग्री हल कर रहे हैं, व्यवस्थित, नतीजा यह है कि वे और बाद प्रसंस्करण प्रस्तुत करने के लिए आसान कर रहे हैं के साथ द्वारा आविष्कार किया गया था। वहाँ तीन मुख्य किस्में हैं - डेटाबेस संबंधपरक, पदानुक्रमित, नेटवर्क का आवंटन।
मौलिक मॉडल
डेटाबेस के निर्माण पर लौटने, यह लायक हैयह कहने के लिए कि यह प्रक्रिया अपेक्षाकृत जटिल थी, यह प्रोग्राम करने योग्य सूचना प्रसंस्करण उपकरणों के विकास से शुरू होती है। इसलिए यह आश्चर्य की बात नहीं है कि इस समय उनके मॉडल की संख्या 50 से अधिक तक पहुंच जाती है, लेकिन मुख्य रूप से पदानुक्रमिक, संबंधपरक और नेटवर्क हैं, जिनका अभ्यास अभी भी व्यापक रूप से किया जाता है। वे क्या हैं
पदानुक्रमित डेटाबेस में एक पेड़ हैसंरचना और विभिन्न स्तरों के डेटा से संकलित किया गया है, जिसके बीच लिंक हैं। डेटाबेस का नेटवर्क मॉडल एक और जटिल टेम्पलेट है। इसकी संरचना एक पदानुक्रमिक संरचना जैसा दिखता है, और योजना का विस्तार और परिष्कृत किया गया है। उनके बीच का अंतर यह है कि पदानुक्रमित मॉडल का वंशानुगत डेटा केवल एक पूर्वजों से जुड़ा जा सकता है, और नेटवर्क में कई हो सकते हैं। संबंधपरक डेटाबेस की संरचना बहुत जटिल है। इसलिए, इसे अधिक विस्तार से अलग किया जाना चाहिए।

एक संबंधपरक डेटाबेस की मूल अवधारणा
यह मॉडल 1 9 70 के दशक में विकसित किया गया थाविज्ञान के डॉक्टर एडगर कोडड। यह एक तार्किक रूप से संरचित तालिका है जिसमें डेटा का वर्णन करने वाले फ़ील्ड, स्वयं के बीच उनके संबंध, उन पर किए गए संचालन, और सबसे महत्वपूर्ण बात यह है कि नियम जो उनकी ईमानदारी की गारंटी देते हैं। मॉडल को रिलेशनल क्यों कहा जाता है? यह आंकड़ों के बीच संबंधों (लैटिन रिलेटियो से) पर आधारित है। इस प्रकार के डेटाबेस की कई परिभाषाएं हैं। सूचना के साथ संबंधपरक तालिकाओं को व्यवस्थित करना और नेटवर्क या पदानुक्रमित मॉडल की तुलना में प्रसंस्करण देना बहुत आसान है। यह कैसे किया जा सकता है? संबंधों, मॉडल संरचना और संबंधपरक तालिकाओं के गुणों को जानना पर्याप्त है।

मॉडलिंग और बुनियादी तत्वों को लिखने की प्रक्रिया
अपना खुद का डीबीएमएस बनाने के लिए, आपको चाहिएमॉडलिंग टूल में से एक का उपयोग करें, इस बारे में सोचें कि आपको किस जानकारी के साथ काम करने की ज़रूरत है, डिज़ाइन टेबल और रिलेशनल एक- और डेटा के बीच कई रिश्ते, इकाई कोशिकाओं को भरें और प्राथमिक, विदेशी कुंजी स्थापित करें।
टेबल मॉडलिंग और संबंधपरक डिजाइनडेटाबेस को वर्कबेंच, PhpMyAdmin, केस स्टूडियो, डीबीफ़ोर स्टूडियो जैसे निःशुल्क टूल का उपयोग करके बनाया जाता है। विस्तृत डिज़ाइन के बाद, आपको ग्राफिकल तैयार रिलेशनल मॉडल को सहेजना चाहिए और इसे एक तैयार किए गए SQL कोड में अनुवाद करना चाहिए। इस चरण में, आप डेटा सॉर्टिंग, प्रसंस्करण और व्यवस्थितकरण के साथ काम करना शुरू कर सकते हैं।

संबंध मॉडल से जुड़े विशेषताएं, संरचना और शर्तें
प्रत्येक स्रोत अपने तत्वों को अपने तरीके से वर्णित करता है, इसलिए कम भ्रम के लिए मैं थोड़ा संकेत देना चाहता हूं:
- संबंधपरक लेबल = इकाई;
- लेआउट = विशेषताएं = फ़ील्ड नाम = इकाई कॉलम हैडर;
- इकाई उदाहरण = तालिका के tuple = रिकॉर्ड = पंक्ति;
- विशेषता मान = इकाई सेल = फ़ील्ड।

एक रिलेशनल डेटाबेस के गुणों पर नेविगेट करने के लिए, किसी को पता होना चाहिए कि इसमें कौन से मूल घटक हैं और उनका क्या उद्देश्य है।
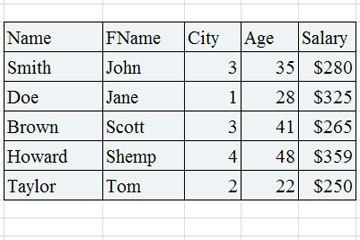
- सार। संबंधपरक डेटाबेस तालिका एक हो सकती है, या उन तालिकाओं का एक पूरा सेट हो सकता है जो उनके द्वारा संग्रहीत डेटा के कारण वर्णित वस्तुओं को चित्रित करते हैं। उनके पास निश्चित संख्या में फ़ील्ड और प्रविष्टियों की एक चर संख्या है। संबंधपरक डेटाबेस मॉडल की तालिका पंक्तियों, विशेषताओं और लेआउट से बना है।
- एक रिकॉर्ड डेटा प्रदर्शित करने वाली रेखाओं की एक चरणीय संख्या है जो वर्णित वस्तु को चिह्नित करता है। प्रविष्टियों की संख्या स्वचालित रूप से सिस्टम द्वारा की जाती है।
- गुण डेटा हैं जो इकाई कॉलम का विवरण प्रदर्शित करता है।
- फील्ड। एक इकाई कॉलम का प्रतिनिधित्व करता है। उनकी संख्या एक तालिका के निर्माण या संशोधन के दौरान एक निश्चित मूल्य सेट है।
अब, तालिका के घटक तत्वों को जानना, आप संबंधपरक डेटाबेस मॉडल के गुणों पर जा सकते हैं:
- एक संबंधपरक डेटाबेस की इकाइयां द्वि-आयामी हैं। इस संपत्ति के लिए धन्यवाद, उनके साथ विभिन्न तार्किक और गणितीय परिचालन करना आसान है।
- एक संबंधित तालिका में विशेषता मानों और अभिलेखों का क्रम मनमाना हो सकता है।
- एक एकल संबंध तालिका में एक कॉलम का अपना व्यक्तिगत नाम होना चाहिए।
- इकाई कॉलम में मौजूद सभी डेटा की निश्चित लंबाई और एक ही प्रकार है।
- संक्षेप में किसी भी रिकॉर्ड को एक डेटा आइटम माना जाता है।
- तारों के घटक घटक अद्वितीय हैं। संबंधपरक इकाई में कोई समान पंक्तियां नहीं हैं।
एक रिलेशनल डीबीएमएस के गुणों के आधार पर, यह स्पष्ट है कि विशेषता मान समान प्रकार, लंबाई का होना चाहिए। विशेषता मानों की विशेषताओं पर विचार करें।
संबंधपरक डेटाबेस फ़ील्ड की मुख्य विशेषताएं
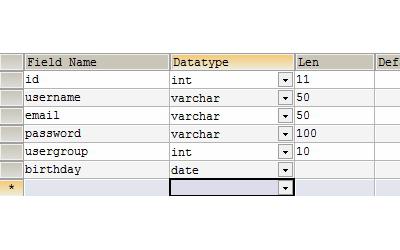
फील्ड नामों के भीतर अद्वितीय होना चाहिएएक इकाई संबंधपरक डेटाबेस के गुण या फ़ील्ड प्रकार बताते हैं कि इकाई फ़ील्ड में किस श्रेणी का डेटा संग्रहीत किया जाता है। रिलेशनल डेटाबेस फ़ील्ड में निश्चित आकार होना चाहिए, वर्णों में गणना की जानी चाहिए। विशेषता मानों के पैरामीटर और प्रारूप निर्धारित करते हैं कि डेटा को किस प्रकार सही किया गया है। "मास्क" या "इनपुट टेम्पलेट" जैसी कोई चीज़ भी है। यह एक विशेषता मान के लिए इनपुट डेटा कॉन्फ़िगरेशन को परिभाषित करना है। निश्चित रूप से फ़ील्ड में गलत डेटा प्रकार लिखते समय एक त्रुटि अधिसूचना दी जानी चाहिए। फील्ड तत्वों पर भी कुछ प्रतिबंध हैं - डेटा प्रविष्टि की सटीकता और सटीकता की जांच करने की शर्तें। कुछ अनिवार्य विशेषता मान है जो विशिष्ट रूप से डेटा से भरा होना चाहिए। कुछ विशेषता तारों को नल मानों से भरा जा सकता है। इसे फ़ील्ड विशेषताओं में खाली डेटा दर्ज करने की अनुमति है। त्रुटि अधिसूचना की तरह, ऐसे मान हैं जो सिस्टम द्वारा स्वचालित रूप से भर जाते हैं - यह डिफ़ॉल्ट डेटा है। किसी भी डेटा की खोज तेज करने के लिए, एक अनुक्रमित फ़ील्ड का इरादा है।
एक द्वि-आयामी संबंधपरक डेटाबेस तालिका का चित्र
| विशेषता नाम 1 | विशेषता नाम 2 | विशेषता नाम 3 | विशेषता नाम 4 | विशेषता नाम 5 |
| Element_1_1 | Element_1_2 | Element_1_3 | Element_1_4 | Element_1_5 |
| Element_2_1 | Element_2_2 | Element_2_3 | Element_2_4 | Element_2_5 |
| Element_3_1 | Element_3_2 | Element_3_3 | Element_3_4 | Element_3_5 |
नियंत्रण प्रणाली की विस्तृत समझ के लिएएसक्यूएल का उपयोग करने वाले मॉडल उदाहरण के अनुसार योजना पर विचार करना सबसे अच्छा है। हम पहले से ही जानते हैं कि एक संबंधपरक डेटाबेस क्या है। प्रत्येक तालिका में प्रविष्टि एक डेटा आइटम है। डेटा अनावश्यकता को रोकने के लिए, सामान्यीकरण संचालन करना आवश्यक है।
संबंध इकाई सामान्यीकरण के लिए बुनियादी नियम
1. एक संबंध तालिका के लिए फ़ील्ड नाम का मान अद्वितीय होना चाहिए, एक प्रकार का (पहला सामान्य रूप 1 एनएफ है)।
2. किसी तालिका के लिए जो पहले ही 1 एनएफ में परिवर्तित हो चुका है, किसी भी गैर-पहचान कॉलम का नाम तालिका (2 एनएफ) के अद्वितीय पहचानकर्ता पर निर्भर होना चाहिए।
3. पूरी तालिका के लिए, जो पहले से ही 2 एनएफ में है, प्रत्येक गैर पहचानने वाला फ़ील्ड किसी अन्य अपरिचित मान (3 एनएफ इकाई) के तत्व पर निर्भर नहीं हो सकता है।
डेटाबेस: तालिकाओं के बीच संबंध संबंध
संबंधपरक तालिका संबंध लिंक के 2 मुख्य प्रकार हैं:
- "कई लोगों के लिए।" ऐसा होता है जब तालिका संख्या 1 की एक प्रमुख प्रविष्टि दूसरी इकाई के कई उदाहरणों से मेल खाती है। खींची गई रेखा के सिरों में से एक पर मुख्य आइकन इंगित करता है कि इकाई "एक" तरफ है, रेखा के दूसरे छोर को अक्सर एक अनंत प्रतीक के साथ चिह्नित किया जाता है।

- इस घटना में एक "कई-कई" रिश्ते बनते हैं कि एक इकाई के कई पंक्तियों के बीच एक और तालिका के कई रिकॉर्ड के साथ एक स्पष्ट तार्किक बातचीत होती है।
- यदि दो इकाइयों के बीच उत्पन्न होता हैconcatenation "एक से एक" है, जिसका अर्थ है कि एक तालिका की मुख्य पहचानकर्ता किसी अन्य इकाई में मौजूद है, तो तालिकाओं में से एक को हटा दिया जाना चाहिए, यह अनावश्यक है। लेकिन कभी-कभी प्रोग्रामर सुरक्षा कारणों से जानबूझकर दो इकाइयों को अलग करते हैं। इसलिए, अनुमानित रूप से, एक-से-एक संबंध मौजूद हो सकता है।
एक संबंधपरक डेटाबेस में कुंजी का अस्तित्व
प्राथमिक और माध्यमिक कुंजी परिभाषित करेंसंभावित डेटाबेस संबंध। डेटा मॉडल के रिलेशनल रिश्तों में केवल एक संभावित कुंजी हो सकती है, यह प्राथमिक कुंजी होगी। वह कैसा है एक प्राथमिक कुंजी एक इकाई कॉलम या विशेषता सेट है जो आपको किसी विशिष्ट पंक्ति से डेटा तक पहुंचने की अनुमति देती है। यह अद्वितीय, अद्वितीय होना चाहिए, और इसके क्षेत्रों में खाली मूल्य नहीं हो सकते हैं। यदि प्राथमिक कुंजी में केवल एक विशेषता होती है, तो इसे सरल कहा जाता है, अन्यथा यह एक घटक होगा।
प्राथमिक कुंजी के अलावा, एक बाहरी भी है(विदेशी कुंजी)। बहुत से लोग समझ नहीं पाते कि उनके बीच क्या अंतर है। उदाहरण के लिए हम उन्हें अधिक विस्तार से विश्लेषण करते हैं। तो, 2 टेबल हैं: "डीन का कार्यालय" और "छात्र"। इकाई "डीन के कार्यालय" में फ़ील्ड शामिल हैं: "छात्र आईडी", "पूर्ण नाम" और "समूह"। "छात्र" तालिका में "पूर्ण नाम", "समूह" और "औसत गेंद" जैसे गुण मान होते हैं। चूंकि छात्र आईडी कई छात्रों के लिए समान नहीं हो सकती है, इसलिए यह क्षेत्र प्राथमिक कुंजी होगी। "छात्र" तालिका से "पूर्ण नाम" और "समूह" कई लोगों के लिए समान हो सकता है, वे "डीन की इकाई" इकाई से छात्र आईडी संख्या का संदर्भ लेते हैं, इसलिए उन्हें विदेशी कुंजी के रूप में उपयोग किया जा सकता है।
नमूना रिलेशनल डेटाबेस मॉडल
स्पष्टता के लिए, हम एक संबंधपरक डेटाबेस मॉडल का एक सरल उदाहरण देते हैं जिसमें दो इकाइयां शामिल हैं। "डीन" नाम वाली एक टेबल है।
सार "डीन" | ||
छात्र आईडी | पूरा नाम | समूह |
111 | इवानोव ओलेग पेट्रोविच | में-41 |
222 | Lazarev Ilya Aleksandrovich | में -72 |
333 | Konoplev पीटर Vasilyevich | में-41 |
444 | कुशनेरे नतालिया इगोरवना | में -72 |
आपको प्राप्त करने के लिए एक कनेक्शन पकड़ने की जरूरत हैपूर्ण संबंधपरक डेटाबेस। प्रविष्टि "IN-41", साथ ही साथ "IN-72" प्लेट "डीन के कार्यालय" में एक से अधिक बार मौजूद हो सकती है, साथ ही साथ अंतिम नाम, दुर्लभ मामलों में छात्रों का पहला नाम और पेट्रोनेरिक भी हो सकता है, इसलिए इन क्षेत्रों को प्राथमिक कुंजी नहीं बनाया जा सकता है। हम "छात्र" का सार दिखाते हैं।
"छात्र" टेबल | |||
पूरा नाम | समूह | औसत गेंद | फोन नंबर |
इवानोव ओलेग पेट्रोविच | में-41 | 3,0 | 2-27-36 |
Lazarev Ilya Aleksandrovich | में -72 | 3,8 | 2-36-82 |
Konoplev पीटर Vasilyevich | में-41 | 3,9 | 2-54-78 |
कुशनेरे नतालिया इगोरवना | में -72 | 4,7 | 2-65-25 |
जैसा कि हम देख सकते हैं, संबंधित प्रकार के संबंधपरक डेटाबेसपूरी तरह से अलग है। डिजिटल प्रविष्टियां और चरित्र दोनों हैं। इसलिए, विशेषता सेटिंग्स में आपको मान पूर्णांक, चार, वाचर, दिनांक और अन्य निर्दिष्ट करना चाहिए। "डीन" तालिका में, केवल छात्र आईडी एक अद्वितीय मूल्य है। इस क्षेत्र को प्राथमिक कुंजी के रूप में लिया जा सकता है। "छात्र" इकाई का पूरा नाम, समूह और फ़ोन नंबर एक विदेशी कुंजी के रूप में लिया जा सकता है जो छात्र आईडी को संदर्भित करता है। कनेक्शन की स्थापना की। यह एक-से-एक मॉडल का एक उदाहरण है। Hypothetically, तालिकाओं में से एक अनिवार्य है, वे आसानी से एक इकाई में जोड़ा जा सकता है। छात्र आईडी को सार्वभौमिक रूप से ज्ञात होने से रोकने के लिए, दो तालिकाओं का अस्तित्व काफी यथार्थवादी है।





